Adversarial Search in AI
Table of Content:
- What is the adversarial search?
- Types of Games in AI
- Zero-Sum Games
- Formalization of the problem
- Game tree
- Example: Tic-Tac-Toe game tree
- Example Explanation of Game tree
Content Highlight:
Adversarial search in AI involves finding optimal strategies in competitive environments like games, considering opponent moves. Games can be perfect or imperfect information, deterministic or non-deterministic, influencing gameplay dynamics. Zero-sum games entail competitive scenarios like Chess or Tic-Tac-Toe, where one player's gain equals another's loss. Formalization in AI games defines initial states, actions, transitions, terminal tests, and utilities to guide decision-making. The Minimax technique aims to find optimal strategies by propagating minimax values, employing depth-first search.
What is the adversarial search?
Adversarial search is a problem-solving technique used in artificial intelligence, particularly in the context of game playing, where an agent is required to make decisions in a competitive environment against one or more opponents. The goal of adversarial search is to find the best possible move or strategy for the agent given the actions and potential reactions of the opponents.
In adversarial search, the agent considers the possible moves it can make, as well as the possible moves its opponents can make in response, and tries to choose the move that maximizes its chances of success or minimizes its chances of failure. This often involves evaluating different possible future game states, typically through the use of algorithms such as minimax or alpha-beta pruning.
Adversarial search is commonly applied in board games like chess, checkers, and Go, as well as in other competitive domains such as card games and strategic planning. It's a fundamental concept in AI, providing a framework for decision-making in situations where multiple agents have conflicting objectives.
Types of Games in AI:
| Deterministic | Chance Moves | |
|---|---|---|
| Perfect information | Chess, Checkers, go, Othello | Backgammon, monopoly |
| Imperfect information | Battleships, blind, tic-tac-toe | Bridge, poker, scrabble, nuclear war |
- Perfect Information Games: Games characterized by perfect information grant players complete access to all relevant details of the game state. In these games, players have full knowledge of the current board layout and can observe all moves made by their opponents. Prominent examples of perfect information games include classics like Chess, Checkers, and Go. In these strategic contests, players strategize based on a clear understanding of the entire game state, fostering a deep level of tactical engagement.
- Imperfect Information Games: In contrast, games with imperfect information present players with partial or limited knowledge about the game state. In such games, players may be unaware of certain elements or developments occurring within the game. Examples of games with imperfect information include Tic-Tac-Toe, Battleship, and card games like Poker. In these scenarios, players must navigate uncertainty and adapt their strategies dynamically in response to unfolding events, adding an element of suspense and strategic complexity.
- Deterministic Games: Deterministic games adhere strictly to defined rules and exhibit no element of randomness or chance. Moves and outcomes in deterministic games are entirely predictable based on the game's structure and player decisions. Classic examples of deterministic games include Chess, Checkers, Go, and Tic-Tac-Toe. Players engage in these games with the assurance that every action has a predetermined consequence, emphasizing strategic planning and foresight.
- Non-Deterministic Games: Non-deterministic games introduce elements of randomness or chance, resulting in unpredictable outcomes and variability in gameplay. Factors such as dice rolls or card draws contribute to the element of uncertainty, making each action's outcome uncertain. Games like Backgammon, Monopoly, and Poker exemplify non-deterministic gameplay, where players must adapt their strategies to account for the inherent unpredictability, adding excitement and unpredictability to the gaming experience.
Note: In this topic we'll talk about deterministic games, fully observable environments, zero-sum games, and where each agent acts alternately.
Zero-Sum Games:
- Zero-Sum games represent competitive scenarios where one player's gain directly corresponds to another player's loss.
- In a zero-sum game, each player's change in utility perfectly offsets the other player's change, resulting in a balance between gains and losses.
- One player aims to maximize a single value, while the other seeks to minimize it, creating a dynamic of strategic competition.
- Each action taken by a player during the game is termed a ply, contributing to the unfolding strategy and outcome.
- Notable examples of zero-sum games include classic board games like Chess and Tic-Tac-Toe, where players engage in intense strategic battles to outmaneuver their opponents.
Zero-sum game: Embedded thinking:-
The Zero-sum game entails embedded reasoning, in which one agent or player attempts to determine:
- What to do: In the game, each player must determine their next move strategically.
- How to decide the move: Players decide their moves by carefully assessing the game state and considering various strategic options.
- Needs to think about his opponent as well: Players must also anticipate their opponent's possible moves and plan accordingly to counteract their strategies.
- The opponent also thinks what to do: Similarly, opponents analyze the game situation and strategize their moves to achieve their objectives.
Each player is trying to figure out how his opponent will react to his moves. To address gaming problems in AI, this necessitates embedded thinking or backward reasoning.
Formalization of the problem:
A game is a type of AI search that can be structured into the following elements:
- Initial State: This defines how the game is set up at the beginning, establishing the starting conditions.
- Player(s): Specifies which player is currently making moves within the game's state space.
- Action(s): Represents the set of legal moves available to a player within the current state space of the game.
- Result(s, a): This transition model outlines the outcome of a particular move within the state space, determining the new state after the move.
- Terminal Test(s): The terminal test evaluates whether the game has concluded, returning true if the game is over and false otherwise. Terminal states mark the conclusion of the game.
- Utility(s, p): The utility function assigns a numerical value to the final outcome of the game for a given player in terminal states. Also known as the payoff function, it quantifies the success or failure of a player's strategy. For instance, in Chess, outcomes may result in a win (+1), loss (0), or draw (½). In Tic-Tac-Toe, utility values can be +1 for a win, -1 for a loss, and 0 for a draw.
Game tree:
A game tree is a tree in which the nodes represent game states and the edges represent player moves. Initial state, actions function, and result function are all part of the game tree.
Example: Tic-Tac-Toe game tree:
The following are some of the game's most important features of Tic-Tac-Toe game tree.
- There are two players MAX and MIN.
- Players have an alternate turn and start with MAX.
- MAX maximizes the result of the game tree
- MIN minimizes the result.
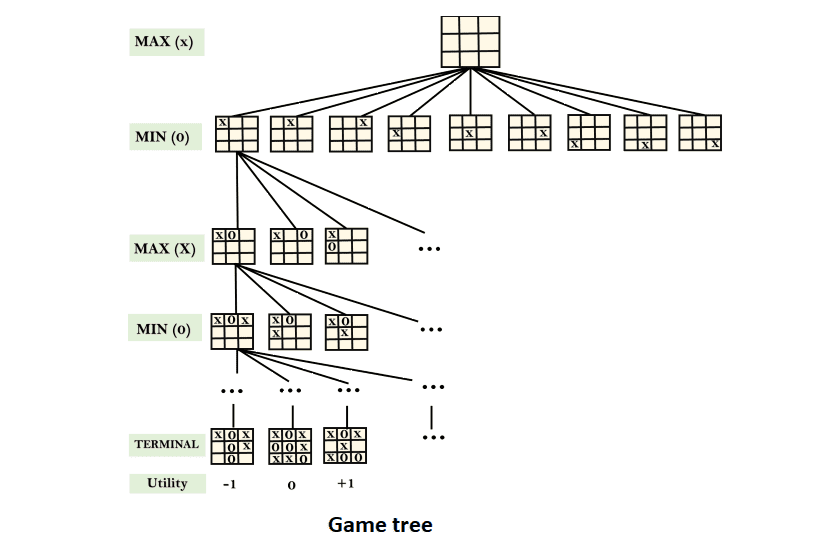
Example Explanation of Game tree:
- From the initial state, MAX has 9 possible moves as they start first in the game of Tic-Tac-Toe. MAX places 'X' and MIN places 'O', with both players taking turns until reaching a leaf node where one player achieves three in a row or all squares are filled.
- Both players employ the minimax algorithm, evaluating each node to determine the best achievable utility against an optimal adversary. Each player is well-versed in the game and strives to prevent their opponent from winning. MIN acts as an adversary against MAX, ensuring competitive gameplay.
- The game tree consists of alternating layers of MAX and MIN, with each layer representing a ply. MAX places 'X', followed by MIN placing 'O' to block MAX from winning. This sequence continues until reaching a terminal node.
- The possible outcomes include a victory for MIN, a victory for MAX, or a draw. The game tree encompasses all possible scenarios as MIN and MAX engage in strategic gameplay, alternating turns in a game of Tic-Tac-Toe.
As a result, the adversarial Search for the Minimax technique is:
- It aims to find the optimal strategy for MAX to win the game.
- It follows the approach of Depth-first search.
- In the game tree, optimal leaf node could appear at any depth of the tree.
- Propagate the minimax values up to the tree until the terminal node discovered.
The optimal strategy in a particular game tree can be determined by looking at the minimax value of each node, which can be expressed as MINIMAX (n). MAX prefers to move to a maximum value state, while MIN prefers to move to a minimum value state, so:
