Machine Learning vs. Data Science
Table of Content:
- Understanding Data Science
- Key Components of Data Science
- Applications of Data Science
- What is Machine Learning?
- Key Types of Machine Learning
- Applications of Machine Learning
- Data Science vs. Machine Learning: How Do They Differ?
- How Data Science and Machine Learning Work Together
- Conclusion: The Symbiotic Relationship Between Data Science and Machine Learning
Content highlight:
Data Science and Machine Learning, though often used interchangeably, serve different purposes within the tech landscape. Data Science focuses on extracting valuable insights from raw data using statistical analysis, while Machine Learning is a specialized branch of AI that enables machines to learn from data and make predictions autonomously. Together, they drive innovation in industries like healthcare, finance, e-commerce, and entertainment by automating decision-making processes and providing businesses with data-driven insights. This comprehensive guide explores their distinct roles, applications, and how they work in tandem to solve complex problems in a data-driven world.
Difference Between Data Science and Machine Learning: A Comprehensive Guide for 2024
Data Science and Machine Learning are two of the most transformative fields in modern technology, both driving innovation and change across a range of industries. These terms are frequently mentioned alongside other technological buzzwords such as Artificial Intelligence (AI) and Deep Learning. However, despite the close relationship between them, Data Science and Machine Learning have distinct differences. For professionals and enthusiasts alike, it is important to recognize these differences and understand how the two complement one another.
As we delve into this comprehensive guide, we’ll explore what distinguishes Data Science from Machine Learning, discuss how these technologies are employed in various industries, and provide real-world examples to highlight their significance in solving complex problems in a data-driven world.
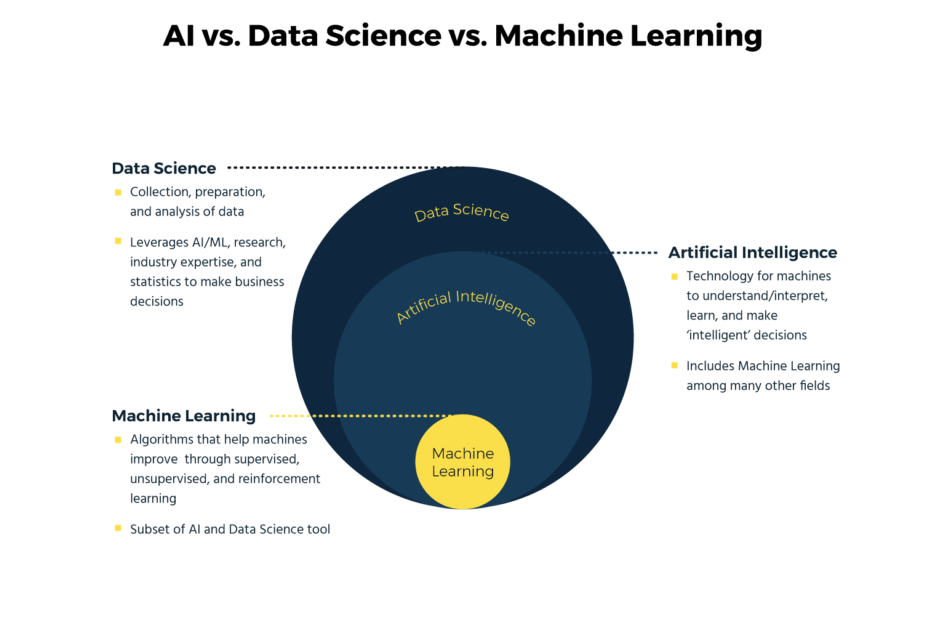
Understanding Data Science:
Data Science is the interdisciplinary study of data. It focuses on processes that are used to extract meaningful insights and knowledge from raw data. Data Science encompasses a wide variety of techniques and tools that are grounded in fields such as statistics, mathematics, and computer science. At its core, Data Science involves managing and analyzing vast amounts of data, commonly referred to as Big Data.
The key objective of Data Science is to transform unstructured and structured data into actionable intelligence. Data scientists use a mix of programming, statistical analysis, and machine learning to analyze data and make informed predictions, as well as to derive insights that can drive business strategy, product development, and decision-making.
For instance, companies like Netflix leverage Data Science to recommend shows and movies to their users. By analyzing viewer habits and patterns, Netflix can provide personalized recommendations that enhance the user experience, ultimately leading to higher retention rates and customer satisfaction.
Key Components of Data Science:
Data Science includes several stages, each of which plays a crucial role in the process of analyzing and deriving insights from data. Below are the key components of Data Science:
- Data Collection: Data scientists collect raw data from a wide range of sources such as databases, social media, IoT devices, and sensors. The data can be structured, semi-structured, or unstructured.
- Data Cleaning: Before the data can be analyzed, it must be cleaned to ensure accuracy. This involves handling missing data, removing outliers, and correcting inconsistencies.
- Data Exploration: Exploratory Data Analysis (EDA) is used to understand the data better. It allows data scientists to uncover trends, correlations, and hidden patterns using statistical and visualization techniques.
- Data Modeling: During this phase, data scientists build models that describe or predict a given phenomenon. These models may be statistical models or machine learning models, depending on the nature of the data and the goals of the analysis.
- Data Visualization: Once the insights have been extracted, data visualization tools like Tableau, Power BI, or Python libraries (Matplotlib, Seaborn) are used to create visual representations that make it easier to communicate findings to stakeholders.
- Deployment: Once a model has been created, it is deployed into production where it is used to make real-time decisions or predictions. Monitoring is then performed to ensure the model performs effectively.
These stages reflect the iterative and collaborative nature of Data Science. Data scientists often revisit earlier stages as they refine their analysis or adjust models to better fit the data.
Applications of Data Science:
Data Science is widely applied across various industries. In fact, it has become a core aspect of many modern businesses. Some of the key applications include:
- Healthcare: In healthcare, Data Science is used for predictive analytics to anticipate patient outcomes, optimize treatment plans, and improve disease diagnosis through machine learning models.
- Finance: Financial institutions use Data Science for fraud detection, credit scoring, and optimizing investment strategies by analyzing large datasets related to financial transactions and market trends.
- E-commerce: Companies like Amazon and eBay utilize Data Science for product recommendations, customer segmentation, and optimizing logistics and supply chains based on purchasing behavior and trends.
- Marketing: In digital marketing, Data Science helps companies target the right audiences, predict consumer behavior, and optimize ad campaigns through data-driven insights.
- Energy: The energy industry uses Data Science to optimize power grid performance, forecast energy demand, and improve the efficiency of renewable energy sources.
What is Machine Learning?
Machine Learning (ML) is a specialized branch of Artificial Intelligence (AI) that focuses on enabling machines to learn from data and improve their performance over time. Unlike traditional programming, where rules and logic are explicitly defined, Machine Learning models are trained on data to make decisions autonomously. These models detect patterns and relationships in the data to make predictions, identify trends, or even recognize objects in images.
Machine Learning is particularly powerful because it allows systems to generalize from past experiences (data) and apply this knowledge to new, unseen data without the need for human intervention. As more data becomes available, ML models can continuously improve their accuracy.
Key Types of Machine Learning:
There are several types of Machine Learning, each suited to different tasks and data types. The three primary types of Machine Learning are:
- Supervised Learning: In supervised learning, the model is trained on labeled data, meaning that each data point is associated with a corresponding output. The model learns to map inputs to outputs and is then tested on new, unseen data. Examples include classification tasks like email spam detection and regression tasks like predicting house prices.
- Unsupervised Learning: Unsupervised learning deals with unlabeled data, meaning that the model must find patterns or clusters in the data without explicit guidance. This approach is often used for clustering or anomaly detection, such as grouping customers based on purchasing behavior.
- Reinforcement Learning: In reinforcement learning, the model interacts with an environment and learns by receiving feedback in the form of rewards or penalties. This type of learning is commonly used in game AI, robotics, and autonomous vehicles.
The wide range of Machine Learning techniques enables it to be applied across various domains and industries. For example, recommendation systems, fraud detection, and even self-driving cars all rely heavily on ML models.
Applications of Machine Learning:
Like Data Science, Machine Learning has widespread applications across industries. Some key use cases include:
- Healthcare: ML models are used to predict patient outcomes, analyze medical images (e.g., X-rays, MRIs), and even develop personalized treatment plans based on genetic data.
- Finance: Machine Learning models are employed to detect fraudulent transactions, optimize stock portfolios, and assess risk in lending processes.
- Retail: Retailers use ML to recommend products, forecast demand, and optimize supply chains based on historical purchasing behavior and trends.
- Transportation: Autonomous vehicles rely heavily on reinforcement learning and computer vision to navigate and make real-time decisions on the road.
- Customer Support: Many companies now employ Machine Learning to power chatbots and virtual assistants, which provide instant responses to customer queries and enhance the customer experience.
Data Science vs. Machine Learning: How Do They Differ?
Although Data Science and Machine Learning are closely related, they serve different purposes within the technological landscape. Here’s a breakdown of the key differences between these two fields:
- Scope: Data Science is a broader field that encompasses the entire data lifecycle, from collection and cleaning to analysis and visualization. Machine Learning, on the other hand, focuses specifically on building models that learn from data.
- Objective: The main goal of Data Science is to extract insights and trends from data to inform decision-making. Machine Learning aims to create models that can make predictions or automate decision-making processes.
- Data Handling: Data scientists work with both structured and unstructured data, whereas Machine Learning models often require structured data to function effectively.
- Tools: Data Science utilizes tools like SQL, Hadoop, Tableau, and programming languages such as Python and R. Machine Learning relies heavily on frameworks like TensorFlow, Scikit-learn, and PyTorch to build and train models.
While Data Science seeks to make sense of data and provide insights, Machine Learning focuses on applying those insights to create predictive models. Together, they form a powerful combination, driving advancements in AI and automation.
How Data Science and Machine Learning Work Together?
Data Science and Machine Learning often work hand-in-hand to solve complex problems. In fact, Machine Learning is considered a key component of the Data Science process. After the data has been collected, cleaned, and explored, Machine Learning models can be applied to predict future outcomes or classify data points.
Here’s how Machine Learning fits into the Data Science workflow:
- Data Collection: Data scientists gather raw data from multiple sources. This data is then preprocessed to ensure it’s in a format suitable for analysis.
- Exploratory Data Analysis: During this phase, data scientists analyze the data to understand its structure, identify key trends, and generate hypotheses.
- Feature Engineering: In this step, features (input variables) are selected or transformed to improve the performance of Machine Learning models.
- Modeling: Machine Learning algorithms are applied to build predictive models based on historical data. This involves training the model, testing it, and fine-tuning it to improve performance.
- Evaluation: Once the model has been trained, its accuracy and performance are evaluated using metrics like accuracy, precision, recall, and F1-score.
- Deployment: After the model has been validated, it is deployed into a production environment where it can make real-time predictions.
Conclusion: The Symbiotic Relationship Between Data Science and Machine Learning
In conclusion, Data Science and Machine Learning are two distinct yet complementary fields. Data Science provides the framework for extracting meaningful insights from data, while Machine Learning enables systems to learn from past data and automate predictions. By working together, these fields unlock new possibilities for businesses, governments, and industries around the world.
As organizations continue to generate vast amounts of data, the demand for professionals skilled in Data Science and Machine Learning will only increase. Whether you are looking to analyze consumer behavior, predict stock prices, or develop AI-powered solutions, mastering the intricacies of both Data Science and Machine Learning will put you at the forefront of the next technological revolution.
By leveraging the strengths of both Data Science and Machine Learning, companies can make more informed decisions, optimize their operations, and gain a competitive edge in today’s fast-paced digital economy.