Unsupervised Machine Learning
Table of Contents:
- What is Unsupervised Learning?
- How Does Unsupervised Learning Work?
- Why Use Unsupervised Learning?
- Types of Unsupervised Learning Algorithms
- Recent Advances in Unsupervised Learning
- Real-World Applications of Unsupervised Learning
- Advantages of Unsupervised Learning
- Disadvantages of Unsupervised Learning
- Future Trends in Unsupervised Learning
Content Highlight:
Unsupervised machine learning is a technique where models learn from unlabeled data without predefined outputs. These models use algorithms like K-Means clustering and decision trees to discover hidden patterns and relationships within the data. This process is key for tasks such as data segmentation, anomaly detection, and dimensionality reduction, offering valuable insights from raw data without human intervention.
What is Unsupervised Learning?
Unsupervised learning is a subset of machine learning where models are tasked with finding patterns from unlabeled data. Unlike supervised learning, where the algorithm learns from data with predefined labels, unsupervised learning works without any supervision, discovering hidden structures within the data. It’s commonly used in tasks such as clustering, dimensionality reduction, and association rule mining.
With unsupervised learning, we aim to identify patterns and relationships within datasets, often revealing insights that may not be visible at first glance. This learning approach is valuable for exploratory data analysis, anomaly detection, and simplifying datasets by reducing their complexity.
How Does Unsupervised Learning Work?
Unsupervised learning follows a different workflow from supervised learning due to the lack of labeled data. Here’s a simplified breakdown of the process:
- Input Data: The model receives unlabeled input data, without predefined classes or outcomes.
- Pattern Recognition: The model applies algorithms to discover hidden patterns, similarities, or structures in the data.
- Dimensionality Reduction: In some cases, algorithms reduce the number of variables while retaining the essential data structure, simplifying large datasets.
- Output: The result could be clusters, association rules, or reduced representations that reveal the underlying structure of the data.
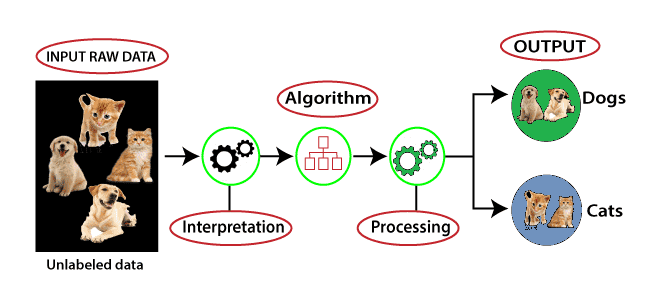
Explanation: In this scenario, we start with unlabeled data, meaning the data is neither categorized nor associated with any specific outputs. This raw input data is then provided to a machine learning model for training. The model's task is to analyze the data and identify underlying patterns without any predefined guidance. It examines the relationships and structures within the dataset, applying algorithms like K-Means clustering, decision trees, or other techniques to group similar data points.
After processing, the algorithm organizes the data into clusters or groups based on shared characteristics and differences, effectively revealing hidden patterns and natural groupings in the data.
Why Use Unsupervised Learning?
There are several reasons why unsupervised learning is crucial in modern data science and machine learning:
- Exploratory Data Analysis: It’s highly valuable for exploring data when we don’t know what patterns or structures exist beforehand.
- Handling Unlabeled Data: Labeling large datasets can be time-consuming and expensive. Unsupervised learning removes this requirement by learning directly from raw, unlabeled data.
- Versatility: It is used across industries for tasks such as customer segmentation, anomaly detection, and product recommendations.
- Identifying Latent Structures: In datasets with no clear boundaries between classes, unsupervised learning identifies latent variables that may not be evident through simple analysis, uncovering hidden patterns and underlying structures in the data.
Types of Unsupervised Learning Algorithms:
Unsupervised learning algorithms generally fall into two categories: clustering and association. Let’s explore these in more detail.
1. Clustering Algorithms:
Clustering is the process of grouping data points into clusters based on their similarities. These algorithms are effective for discovering hidden groupings in data. Some of the most common clustering algorithms include:
- K-Means Clustering: This algorithm groups data into K clusters by minimizing the variance within each cluster. It is highly popular for its simplicity and efficiency in tasks like customer segmentation and image compression.
- Hierarchical Clustering: It forms a hierarchy of clusters by successively merging smaller clusters into larger ones, or vice versa. It can produce a dendrogram, a tree-like diagram that shows the arrangement of the clusters.
- DBSCAN: A density-based clustering method that discovers clusters by analyzing the density of data points in different regions. Unlike K-Means, it doesn't require the user to predefine the number of clusters.
- Gaussian Mixture Models (GMM): GMM assumes that the data is generated from a mixture of several Gaussian distributions. It is a more flexible approach than K-Means, allowing for different shapes and sizes of clusters.
2. Association Rule Learning:
Association rule learning identifies relationships between variables in large datasets. It is often used in market basket analysis to uncover patterns in consumer purchasing behavior. For instance, it can determine that customers who buy bread often purchase butter as well.
- Apriori Algorithm: This algorithm finds frequent itemsets and generates association rules, commonly used in retail for identifying product correlations. It is one of the simplest and most straightforward algorithms for association rule learning.
- Eclat Algorithm: A depth-first search algorithm for frequent itemsets, Eclat is more efficient than Apriori in some scenarios, particularly when the dataset is sparse and large.
- FP-Growth Algorithm: An efficient alternative to Apriori, FP-Growth uses a tree structure to represent itemsets, significantly reducing the number of candidate itemsets compared to Apriori.
Recent Advances in Unsupervised Learning:
As machine learning evolves, recent innovations in unsupervised learning are expanding its capabilities. Two key trends are:
- Deep Clustering: This approach combines deep learning with clustering techniques to better handle high-dimensional data like images and text. Algorithms such as DEC (Deep Embedded Clustering) improve clustering by incorporating feature extraction from neural networks. Deep clustering has gained attention for its application in complex tasks like image segmentation and object detection.
- Self-Supervised Learning: This recent advancement bridges the gap between supervised and unsupervised learning by using the data itself to generate labels. Self-supervised models excel in scenarios where large amounts of unlabeled data are available, especially in fields like computer vision and NLP.
Another noteworthy development is Generative Models like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), which generate new data from a learned distribution. These models have been instrumental in advancing unsupervised learning in areas like image synthesis and data augmentation.
Real-World Applications of Unsupervised Learning:
Unsupervised learning is widely used across industries to solve complex problems. Here are a few key applications:
1. Customer Segmentation:
Businesses use unsupervised learning to segment customers into different groups based on purchasing behavior, demographics, and preferences. This helps in targeted marketing, personalized recommendations, and improving customer satisfaction. For instance, a clustering algorithm like K-Means could be used to segment customers of an e-commerce platform, allowing for better personalization.
2. Anomaly Detection:
Anomaly detection is crucial for identifying unusual behavior in data. It’s used in fraud detection in banking, network intrusion detection in cybersecurity, and even in monitoring industrial equipment for signs of failure. For example, a bank might use unsupervised learning to flag fraudulent credit card transactions that deviate from a customer’s usual spending patterns.
3. Recommendation Systems:
Platforms like Netflix and Amazon use unsupervised learning to build recommendation systems. By analyzing users' behaviors and preferences, algorithms can suggest products, shows, or services that the user is likely to enjoy. Techniques such as collaborative filtering and matrix factorization are often used in these systems.
4. Dimensionality Reduction for Data Visualization:
Dimensionality reduction techniques like Principal Component Analysis (PCA) and t-SNE (t-Distributed Stochastic Neighbor Embedding) are commonly used to reduce the complexity of high-dimensional datasets, making them easier to visualize and understand. These methods are crucial for large datasets where retaining all dimensions isn’t feasible.
Advantages of Unsupervised Learning:
- No Need for Labeled Data: Unsupervised learning can work directly with raw data, eliminating the time and cost of labeling.
- Handles Complex Tasks: It can uncover complex patterns and relationships within large, high-dimensional datasets.
- Adaptable to New Data: Models can easily adapt to new data, making it suitable for dynamic environments where new data streams are constantly arriving.
- Scalable: It’s highly scalable for large datasets and often performs well in real-world settings where labeling is infeasible.
Disadvantages of Unsupervised Learning:
- Hard to Evaluate: Without labeled data, it can be difficult to evaluate the performance of unsupervised models.
- Less Accurate: In some cases, unsupervised learning may yield less accurate results compared to supervised models, especially when the underlying patterns are difficult to discover.
- Computationally Expensive: Clustering large datasets or performing dimensionality reduction can be resource-intensive, requiring significant computational power.
- Interpretability Challenges: Understanding and interpreting the results of unsupervised models can be more challenging due to the lack of explicit labels or clear decision boundaries.
Future Trends in Unsupervised Learning:
The future of unsupervised learning lies in its integration with deep learning and self-supervised learning. As organizations continue to generate massive amounts of data, unsupervised learning models will play an increasingly critical role in making sense of this information, especially in fields such as natural language processing, healthcare, and automated systems.
Researchers are also exploring the use of semi-supervised learning, which combines both labeled and unlabeled data, to enhance the capabilities of unsupervised learning. With advancements in computational power and algorithm efficiency, we can expect unsupervised learning to become even more effective and scalable in the near future.