Supervised vs Unsupervised Learning: Key Differences Explained
Table of Contents:
- Introduction to Machine Learning
- What is Supervised Learning?
- What is Unsupervised Learning?
- Examples of Supervised Learning
- Examples of Unsupervised Learning
- Key Differences Between Supervised and Unsupervised Learning
- Use Cases for Supervised Learning
- Use Cases for Unsupervised Learning
- Choosing the Right Technique for Your Problem
- Modern Algorithms in Supervised and Unsupervised Learning
- Advantages and Disadvantages
- Future of Supervised and Unsupervised Learning
Introduction to Machine Learning
Supervised Machine Learning is a method where models are trained using labeled data to make accurate predictions, commonly applied in tasks like classification, regression, fraud detection, and image recognition. In contrast, Unsupervised Machine Learning works with unlabeled data, enabling models to identify hidden patterns and structures, often used for clustering, market segmentation, anomaly detection, and recommendation systems. Both approaches are essential in extracting meaningful insights from data, with supervised learning focusing on prediction accuracy and unsupervised learning on discovering underlying data relationships.
What is Supervised Learning?
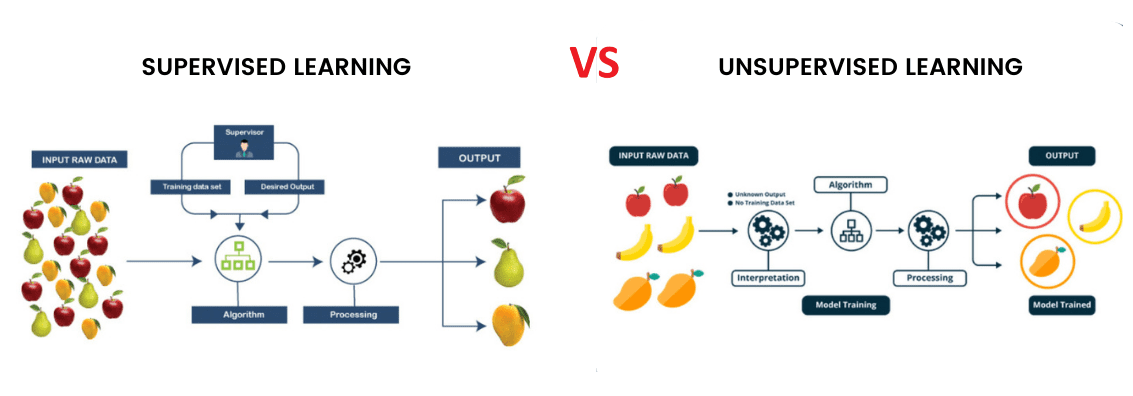
Supervised learning is a type of machine learning where the model is trained using a labeled dataset. This means that for every input in the training dataset, the corresponding output is also provided. The goal of the model is to learn the mapping between inputs and outputs, so it can accurately predict outcomes when given new, unseen data.
In supervised learning, the model is guided by a “teacher” or a set of labeled data, similar to how a student learns with the help of a teacher. The labeled data helps the model to identify patterns and relationships, allowing it to make predictions about new data that follows the same distribution as the training set.
Key Concepts in Supervised Learning:
- Labeled Data: The dataset includes both input features and the correct output, which the model uses to learn.
- Training Phase: The model is trained by mapping the inputs to their corresponding outputs.
- Prediction: After training, the model is used to predict outcomes for new inputs.
- Feedback Loop: During training, the model's predictions are compared to the actual outputs, and adjustments are made to improve accuracy.
- Common Algorithms: Linear Regression, Logistic Regression, Support Vector Machines (SVM), Decision Trees, Random Forests, and Neural Networks.
What is Unsupervised Learning?
Unsupervised learning is a machine learning technique where the model is trained using data that is neither labeled nor categorized. The goal of unsupervised learning is to infer the natural structure present within a set of data points. The model explores the data and identifies patterns, groupings, and relationships without prior knowledge of the outcomes.
In unsupervised learning, the model is on its own to find patterns within the data. This approach is more aligned with how humans often learn—by observation and experimentation without direct instruction. Unsupervised learning is particularly useful in scenarios where the structure of the data is unknown or where labels are difficult or expensive to obtain.
Key Concepts in Unsupervised Learning:
- Unlabeled Data: The dataset consists of input features without corresponding output labels.
- Clustering: Grouping data points into clusters based on their similarities.
- Association: Identifying relationships between variables within the data.
- Dimensionality Reduction: Simplifying the data by reducing the number of variables while preserving its essential structure.
- Common Algorithms: K-Means Clustering, Hierarchical Clustering, Principal Component Analysis (PCA), Apriori Algorithm, and Autoencoders.
Examples of Supervised Learning
Supervised learning is widely used across various industries and applications. Here are some common examples:
- Email Spam Detection: A supervised learning model can be trained to classify emails as spam or not spam based on features such as the email content, sender, and subject line. The labeled dataset consists of emails that are already classified as spam or non-spam, allowing the model to learn the patterns associated with each category.
- Fraud Detection: Financial institutions use supervised learning to detect fraudulent transactions. The model is trained on historical transaction data, where each transaction is labeled as either legitimate or fraudulent. The model then predicts the likelihood of new transactions being fraudulent.
- Customer Churn Prediction: Companies use supervised learning to predict whether a customer is likely to stop using their service. The model is trained on customer data, including usage patterns and demographic information, to identify factors that contribute to churn.
- Image Classification: Supervised learning models can classify images into categories, such as identifying animals in pictures. The model is trained on a labeled dataset of images, where each image is tagged with the correct category.
Examples of Unsupervised Learning
Unsupervised learning is also widely used for a variety of purposes, particularly in scenarios where labeled data is unavailable. Some examples include:
- Market Segmentation: Businesses use unsupervised learning to segment their customers into distinct groups based on purchasing behavior, demographics, and other factors. This helps companies tailor their marketing strategies to specific customer segments.
- Recommendation Systems: Online platforms like Netflix and Amazon use unsupervised learning to recommend products or content to users based on their previous interactions and the behaviors of similar users.
- Document Clustering: In natural language processing (NLP), unsupervised learning is used to group documents with similar content together. This is useful for organizing large collections of text, such as news articles or research papers.
- Anomaly Detection: Unsupervised learning models can detect unusual patterns or outliers in data, such as identifying network intrusions or equipment malfunctions in industrial settings.
Key Differences Between Supervised and Unsupervised Learning
While both supervised and unsupervised learning are integral to machine learning, they differ significantly in their approach, use cases, and outcomes. Below is a comprehensive comparison of the two:
1. Nature of the Data
Supervised learning relies on labeled data, meaning that each training example is paired with an output label. This allows the model to learn the relationship between the input data and the corresponding output. On the other hand,unsupervised learning deals with unlabeled data. The model must identify patterns and structures in the data without any explicit guidance on what the output should be.
2. Goal of the Model
The primary goal ofsupervised learning is to make accurate predictions based on new data. This could involve classifying data into categories, such as identifying whether an email is spam, or predicting continuous outcomes, such as forecasting sales figures. In contrast,unsupervised learning aims to uncover hidden patterns or groupings in the data. The focus is on exploring the data and discovering insights rather than making specific predictions.
3. Learning Process
Insupervised learning, the model learns from a training set where the correct output is known. The model's performance is continually evaluated, and adjustments are made to improve accuracy. Inunsupervised learning, the model receives no such guidance. Instead, it independently identifies structures within the data, such as clusters or associations, without being told what to look for.
4. Feedback Mechanism
Supervised learning involves a feedback loop where the model’s predictions are compared to the actual outputs, and errors are used to refine the model. This iterative process helps the model improve over time. Inunsupervised learning, there is no feedback loop. The model does not receive any direct feedback on its performance because the true labels are unknown.
5. Use Cases
Supervised learning is commonly used in applications where the goal is to predict outcomes based on historical data. This includes tasks like fraud detection, email filtering, and image recognition.Unsupervised learning is used in exploratory data analysis, where the objective is to understand the underlying structure of the data. This includes tasks like customer segmentation, anomaly detection, and market basket analysis.
6. Complexity
Supervised learning models are generally less complex since they have clear guidance in the form of labeled data. The model's task is to learn the relationship between inputs and outputs.Unsupervised learning models, however, can be more complex because they must discern patterns and relationships without any prior knowledge, making the process more challenging.
Use Cases for Supervised Learning
Supervised learning is highly versatile and can be applied in various fields. Some of the most common use cases include:
- Healthcare: Predicting patient outcomes based on medical history and other variables.
- Finance: Credit scoring, fraud detection, and risk management.
- Marketing: Predicting customer behavior and segmenting markets based on historical data.
- Manufacturing: Predictive maintenance to anticipate equipment failures and reduce downtime.
Use Cases for Unsupervised Learning
Unsupervised learning is also widely used across many domains, particularly in scenarios where discovering hidden patterns is essential:
- E-commerce: Recommending products to users based on their browsing history and behavior.
- Cybersecurity: Detecting unusual patterns in network traffic that may indicate a security breach.
- Social Media: Grouping users based on their interactions, interests, and behaviors.
- Genomics: Analyzing genetic data to identify patterns related to diseases and traits.
Choosing the Right Technique for Your Problem
Deciding whether to use supervised or unsupervised learning depends on several factors, including the nature of the data, the specific problem you are trying to solve, and the availability of labeled data.
When to Choose Supervised Learning:
- You have a labeled dataset where each example is paired with the correct output.
- The goal is to make predictions or classifications based on new, unseen data.
- You need a model that can be trained and validated with clear guidance from labeled data.
When to Choose Unsupervised Learning:
- You are dealing with unlabeled data and need to explore the data to find patterns or groupings.
- The goal is to gain insights from the data, such as clustering customers based on their behavior.
- You are interested in reducing the dimensionality of your data for easier visualization or processing.
Modern Algorithms in Supervised and Unsupervised Learning
Both supervised and unsupervised learning have seen significant advancements in recent years. Modern algorithms continue to push the boundaries of what is possible with machine learning.
1. Supervised Learning Algorithms
Gradient Boosting Machines (GBM),Random Forests, andDeep Learning models have revolutionized supervised learning, enabling the handling of large, complex datasets with high accuracy. These models are now standard in applications ranging from image recognition to natural language processing (NLP).
2. Unsupervised Learning Algorithms
In unsupervised learning, the development ofDeep Clustering,Variational Autoencoders (VAEs), andGenerative Adversarial Networks (GANs) has opened new avenues for data exploration. These algorithms are particularly effective in tasks such as generating synthetic data, detecting anomalies, and discovering new patterns in complex datasets.
Advantages and Disadvantages
Both supervised and unsupervised learning have their advantages and disadvantages, depending on the specific application and data.
Supervised Learning
Advantages:
- Predictive Power: High accuracy in predicting outcomes when trained on large, well-labeled datasets.
- Interpretability: Many supervised models, such as decision trees, are easy to interpret and understand.
- Real-World Applications: Widely used in industries like healthcare, finance, and marketing.
Disadvantages:
- Requires Labeled Data: The need for labeled data can be a significant limitation, especially in scenarios where labeling is expensive or time-consuming.
- Overfitting: Supervised models can overfit the training data, leading to poor generalization to new data.
Unsupervised Learning
Advantages:
- Does Not Require Labeled Data: Unsupervised learning can be applied to datasets without labels, making it more flexible and scalable.
- Discovering Hidden Patterns: Effective at uncovering hidden structures within the data, leading to new insights.
Disadvantages:
- Harder to Evaluate: Without labeled data, it can be challenging to evaluate the performance of unsupervised models.
- Less Accurate: Unsupervised learning may produce less accurate results compared to supervised learning, especially in tasks that require precise predictions.
Future of Supervised and Unsupervised Learning
The future of machine learning lies in the continued development and integration of both supervised and unsupervised learning techniques. As data continues to grow in both size and complexity, the demand for more sophisticated models will increase.
Supervised learning will continue to evolve, with advancements indeep learning andreinforcement learning pushing the boundaries of what is possible.Transfer learning, where a model trained on one task is adapted to perform a related task, is also gaining traction as a way to reduce the need for large labeled datasets.
Unsupervised learning will become increasingly important as more organizations look to extract value from large, unlabeled datasets. Innovations inself-supervised learning, where the model creates its own labels, andgenerative models, which can produce new data from learned patterns, will drive the next wave of breakthroughs in unsupervised learning.
The integration of supervised and unsupervised learning into ahybrid approach is also on the horizon, allowing models to leverage the strengths of both methods. This could lead to more accurate and robust machine learning systems capable of tackling a wider range of problems.