Cross Validation in Machine Learning
In this page we will learn Cross Validation in Machine Learning, What is Cross Validation in Machine Learning?, Methods used for Cross Validation, Validation Set Approach, Leave-P-out cross validation, Leave one out cross validation, K-Fold Cross Validation, Stratified k-fold cross validation, Holdout Method, Comparison of Cross-validation to train / test split in Machine Learning, Limitations of Cross Validation, Applications of Cross Validation.
What is Cross Validation in Machine Learning?
Cross validation is a technique for assessing the model's efficiency by training it on a portion of input data and then testing it on a subset of input data that has never been seen before. It's also known as a tool for determining how well a statistical model generalizes to a different dataset.
The necessity to assess the model's stability is always present in machine learning. We can't fit our model on the training dataset alone, which means we can't fit our model on the training dataset alone. We put aside a specific sample of the dataset for this purpose, which was not part of the training dataset. Then, before deploying our model, we test it on that sample, and the entire process is subjected to cross-validation.
As a result, cross-basic validation's processes are:
- As a validation set, set aside a portion of the dataset.
- Using the training dataset, provide training to the model.
- Now use the validation set to assess the model's performance. If the model performs well with the validation set, move on to the next phase; otherwise, look for problems.
Methods used for Cross Validation
There are some common methods that are used for cross validation. These methods are given below:
- Validation Set Approach
- Leave-P-out cross-validation
- Leave one out cross-validation
- K-fold cross validation
- Stratified k-fold cross validation
Validation Set Approach
In the validation set approach, we divide our input dataset into a training set and a test or validation set. The dataset is split 50% between the two subsets.
However, one of the major drawbacks is that we are only using half of the dataset to train our model, which means the model may miss out on critical dataset information. It also has a tendency to produce an underfitted model.
Leave-P-out cross validation
The p datasets are not included in the training data in this method. It indicates that if the original input dataset is n data points, the training dataset will be n-p data points and the validation set will be p data points. This entire process is repeated for all samples, and the average error is determined to determine the model's effectiveness.
This technique does have one disadvantage: it can be computationally challenging for large p.
Leave one out cross validation
This method is identical to leave-p-out cross-validation, except that instead of p, one dataset must be removed from training. It indicates that in this strategy, just one datapoint is reserved for each learning set, while the remaining dataset is used to train the model. For each datapoint, the process is repeated. As a result, for every n samples, we receive n different training sets and n different test sets. It possesses the following characteristics:
- Because all of the data points are used in this method, the bias is minimal.
- Because the process is repeated n times, the execution time is long.
- As we iteratively check against one data point, this strategy leads to a lot of variety in testing the model's efficacy
K-Fold Cross Validation
The K-fold cross-validation Appoach divides the input dataset into K equal-sized groups of samples. Folds are the term for these types of samples. The prediction function uses k-1 folds for each learning set, while the rest of the folds are used for the test set. This strategy is often used in CVs since it is simple to grasp and produces less biased results than other methods.
The following are the steps for k-fold cross-validation:
- K groups were created from the input dataset.
- For each group, write:
- One group will act as the reserve or test data set.
- As the training dataset, use the remaining groupings.
- Fit the model to the training set and assess the model's performance on the test set.
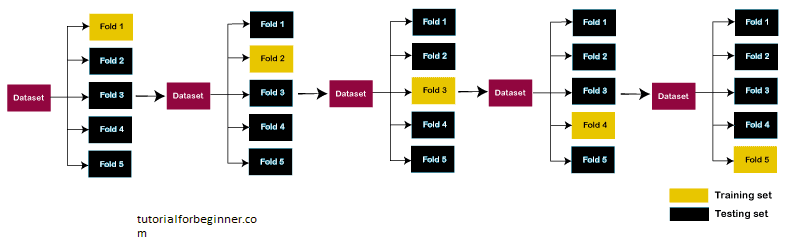
Let's look at a 5-fold cross-validation example. As a result, the data is divided into five folds. On the first iteration, the first fold is set aside for testing the model, while the remaining folds are used to train the model. The second fold is used to test the model on the second iteration, while the remaining folds are utilized to train the model. This process will continue until all of the test folds have been used.
Consider the below diagram:
Stratified k-fold cross validation
With a few minor differences, this technique is similar to k-fold cross-validation. This method is based on the stratification notion, which is the process of rearranging data so that each fold or group is a good representation of the entire dataset. It is one of the most effective methods for dealing with bias and volatility.
It can be illustrated using the example of housing pricing, where the price of some houses can be significantly higher than the price of others. A stratified k-fold cross-validation technique is beneficial in such scenarios.
Holdout Method
This is the most basic cross-validation technique of them all. In this method, we need to remove a subset of the training data and train it on the rest of the dataset to generate prediction results.
Our model's performance with the unknown dataset is determined by the error that occurs during this phase. Although this method is simple to use, it still has a significant level of volatility and can often yield deceptive findings.
Comparison of Cross-validation to train/test split in Machine Learning
-
Train/test split: The input data is separated into
two parts, a training set and a test set, with a 70:30,
80:20, and so on ratio. It has a lot of fluctuation, which
is one of the greatest drawbacks.
- Training Data: The dependent variable is known, and the training data is utilized to train the model.
- Test data: It is used to create predictions using the model that has already been trained on the training data. This has the same characteristics as training data, but it is not a component of it.
- Cross-Validation dataset: By splitting the dataset into groups of train/test splits and averaging the results, the Cross-Validation dataset is utilized to overcome the disadvantage of train/test split. It can be used to tune our model for the optimum performance once it has been trained on the training dataset. When compared to the train/test split, it is more efficient because each observation is used for both training and testing.
Limitations of Cross Validation
The cross validation technique has some limitations, which are listed below:
It produces the best results in perfect conditions. However, due to the inconsistency of the data, it might have a significant impact. As a result, one of the major drawbacks of cross-validation is that there is no guarantee of the type of data used in machine learning.
Because data grows over time in predictive modeling, it may encounter variances between the training and validation sets. For example, if we construct a model for predicting stock market values based on data from the last five years, but the realistic predicted values for the following five years may be substantially different, so it is difficult to expect the correct output for such situations.
Applications of Cross Validation
- This method can be used to compare the results of various predictive modeling techniques.
- It has a lot of potential in the realm of medical research.
- It can also be utilized for meta-analysis, as data scientists in the field of medical statistics are already doing.